Confidential Data Redaction: Ensuring AI Agents Respect Privacy at the Edge
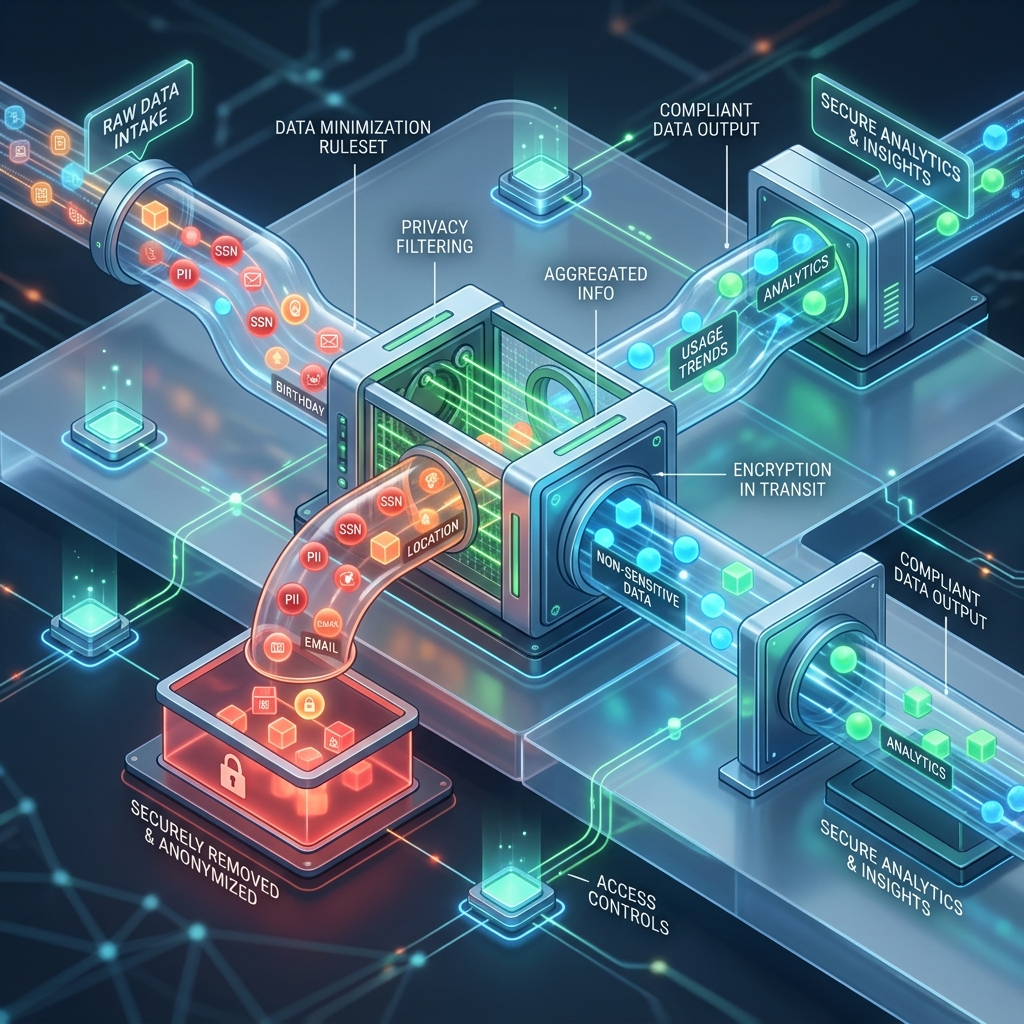
Autonomous agents require access to context. To draft an email reply, an agent needs to read your inbox. To generate a financial report, it needs access to ledger databases. However, feeding this unstructured context directly to third-party LLM APIs creates significant legal risks under GDPR, HIPAA, and PCI-DSS compliance frameworks. To deploy agents safely, developers must implement local, edge-based redaction pipelines that scrub sensitive information before it leaves corporate boundaries.
The Risk of Data Leakage in Prompt Context
When raw text is transmitted to an external API, that data is stored in remote servers and, depending on the provider's terms of service, potentially used for future model training. Personally Identifiable Information (PII) like social security numbers, credit cards, or internal product code names must never be exposed. Redaction must happen at the local application edge—inside the company's VPC—before the prompt is dispatched.
Implementing the Edge Redaction Pattern
A redaction engine intercepts outgoing agent prompts and matches content against a series of high-performance regex profiles and Named Entity Recognition (NER) models. Identified PII is replaced with placeholders (e.g., [REDACTED_NAME]), and a temporary mapping dictionary is preserved locally to re-identify tokens when the model returns a response.
import re
def redact_sensitive_data(prompt: str) -> tuple[str, dict]:
# 1. Define regular expression patterns for standard PII
ssn_pattern = r'\b\d{3}-\d{2}-\d{4}\b'
email_pattern = r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b'
redacted_map = {}
# 2. Match and substitute SSNs
matches = re.findall(ssn_pattern, prompt)
for idx, match in enumerate(matches):
placeholder = f"[SSN_{idx}]"
redacted_map[placeholder] = match
prompt = prompt.replace(match, placeholder)
return prompt, redacted_mapKey Strategies for Secure Context Management
- Deterministic Regex + Local NER: Combine regex filters for structured data (phones, emails, card numbers) with fast local models (like SpaCy) to catch unstructured entities (names, addresses).
- Reversible Tokenization: Retain the mapping index in secure memory locally, so that when the agent returns the output, the placeholders can be swapped back before the user sees the final message.
- Low-Latency Processing: Ensure the scrubbing library is optimized for low CPU footprints to avoid adding latency to the agent pipeline.
Enterprise Data Protection by Default
Implementing an edge redaction layer ensures that third-party LLMs remain reasoning engines, not data archives. By scrubbing sensitive assets before they cross corporate lines, developers satisfy regulatory requirements and secure user data.
Enterprise M&A Inquiry
For technical due diligence or architectural deep-dives into our zero-trust framework, please request access to our tech specs and roadmap.
Request Tech Specs